3 Data Collection, Analysis, Transmission, and Storage
Organization, Documentation, and Metadata
It is important to establish a clear and consistent organization scheme early in data collection projects. Considerations include naming schemes, tracking versions, storage solutions, selections of file types, and the creation of supporting documentation.
Documentation is the supplemental material that provides the information needed to read, understand, identify, and reuse data. These documents may include:
- Readme File
- Data dictionary
- Code book
- Glossary
- Lab notebook
Central to both organization and documentation is metadata, or the descriptive information about the collected data. Metadata provides contextual information surrounding the collected data, indicating the creator, creation date, format, subject, and other important details.
Metadata is meant to be machine-readable, making the data sets findable through databases, search engines, and automated systems. For more details and a discussion of best practice, see Documentation, Organization, Metadata section of the Library Manage Your Research Data guide.
FAIR Data
The ultimate goal of metadata is to make data findable, accessible, interoperable, and reusable, also known as “FAIR Data.” FAIR data is part of the NIH Strategic Plan for Data Science, and both the NIH and NSF are instituting a requirement for all funded research data to be FAIR.
- Findable: data must have unique identifiers, effectively labeling it within searchable resources.
- Accessible: data must be easily retrievable via open systems and effective and secure authentication and authorization procedures.
- Interoperable: data should “use and speak the same language” via use of standardized vocabularies.
- Reusable: data must be adequately described to a new user, have clear information about data-usage licenses, and have a traceable “owner’s manual,” or provenance (NIH, 2018, p.6).
Storage & Backups
You should always have a plan for where and when your data will be backed up. Best practice for backups is to always have three copies of your data:
- The original/active file stored on your computer. This is the file you update daily throughout the course of your work.
- A backup copy on a physical external drive (Ex. disk, jump drive, external hard drive). This should be updated frequently in case your primary work computer is lost.
- A backup file stored on a remote or cloud drive (Ex. shared university drive, cloud storage). This should be updated frequently in case your physical storage devices are lost. This also ensures remote access to files.
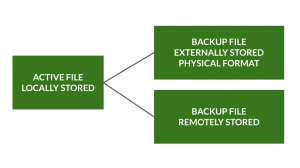
Finally, when a project is concluded and the data is no longer being amended or collected, a final archived copy of the files can be permanently stored in Portland State’s data depository, PDXScholar, or other established data repository.
Advantages of Storing Data on University Operated Resources
PSU employees are expected to store work-related data on University operated resources because it is the only way to ensure that this information is securely stored. It also allows the Office of Information Technology to help researchers with:
- Long term retention
- Timely and appropriate deletion of data
- Transfer of Data
- Removal of access for individuals who leave the institution
- Data recovery
Data recovery is a particularly important consideration, as the University has much less ability to recover lost data that was stored on personal devices as opposed to University operated resources. This can be hugely problematic if the data are sensitive and belong to the University (i.e. contracted research data) as opposed to the individual.
The Office of Information Technology provides a highly functional, widely used campus cyberinfrastructure. This is a thoughtfully integrated environment with mutually accessible file systems for home directory, labs shares, scratch volumes, and web directories to facilitate research work, data storage, and data sharing.
All PSU researchers have access to a minimum of 2TB network storage with backups at no charge. Additional storage available at cost. For more information see Research Computing/Storage.
Research Computing Services
OIT provides servers, data storage, networking and a broad range of software to handle many different computational requirements. These systems provide:
- GPU enabled servers for machine learning and artificial intelligence.
- High-performance compute clusters for multi-node MPI jobs.
- Systems for very long running or compute intensive jobs (Windows and Linux)
- Scratch data storage for active computing and research shares for longer term storage of research data.
- Access to a range of installed research software.
Data Security
Proper security measures for your data are extremely important, particularly if handling data with high or critical risk levels.
In the video Data Security: Research Integrity and Compliance, you will learn about the various types of data that are subject to data security policies. This data security overview will provide you with the information to allow you to discern if there are data security concerns that require a deeper level of assessment by the Data Security and Compliance Officer.
Classifications & Risk
OIT/Research Computing divides data into three primary risks classifications:
Restricted (Critical Risk): Datasets containing SSNs, financial account data such as credit card numbers or cardholder information (CHD), protected health information (PHI), export-controlled data, controlled unclassified data (CUI) governed by a contract or agreement with a third-party agency, or any other data that require by law or regulation the implementation of critical-level security controls.
Confidential (High Risk): Datasets where the unauthorized disclosure, alteration, and/or destruction of that data could result in a significant or high-level risk to our institution or any other data which requires by law, regulation, contract, or agreement the implementation of high-level security controls.
Confidential (Moderate Risk): Non-public datasets containing de-identified data, where the unauthorized disclosure, alteration, and/or destruction of that data could result in a mildly adverse impact to our institution or any other data required by internal policies, standards, and procedures the implementation of moderate-level security controls.
